
模型格式转换:safetensors -> gguf
教程整理自csdn文章 将 HuggingFace 模型转换为 GGUF 及使用 ollama 运行 —— 以 Qwen2-0.5B 为例 和 github的Discussions 教程:如何将 HuggingFace 模型转换为 GGUF 格式
目的和介绍
借助llama.cpp将safetensors格式转gguf
什么是GGUF
GGUF 全称为 GPT-Generated Unified Format ,是一种专为大语言模型设计的二进制文件格式,旨在实现模型的快速加载和保存,同时易于读取。
为什么要转换为GGUF格式
GGUF具有很多优势,包括:
- 单文件部署:模型可以轻松分发和加载,不需要任何外部文件来提供额外信息
- 可拓展性:可以在不破坏与现有模型的兼容性的情况下,向基于GGML的执行器添加新功能或向GGUF模型添加新信息。
- mmap兼容性:可以使用mmap加载模型,以实现快速加载和保存。
- 易于使用:可以使用少量代码轻松加载和保存模型,无论使用何种语言,无需外部库。
- 完整信息:加载模型所需的所有信息都包含在模型文件中,用户无需提供任何额外信息。
模型转换步骤
配置转换环境
- 克隆llama.cpp仓库
git clone https://github.com/ggerganov/llama.cpp.git- 建议使用python虚拟环境,创建新的环境并安装所需依赖库
# conda环境配置
conda create --name llama.cpp python=3.10
conda activate llama.cpp
pip install -r llama.cpp/requirements.txt执行格式转换
- 使用
llama.cpp仓库的convert_hf_to_gguf.py脚本转换
格式
python llama.cpp/convert_hf_to_gguf.py {路径} --outtype {type} --outfile {filepath/filename}全参数转换(无精度损失)
python llama.cpp/convert_hf_to_gguf.py ./models/qwen2.5-1.5b-instruct-merged --outtype f16 --verbose --outfile ./models/qwen2.5-1.5b-instruct_f16.gguf量化转换(推理加速但有精度损失)
python llama.cpp/convert_hf_to_gguf.py ./models/qwen2.5-1.5b-instruct-merged --outtype q8_0 --verbose --outfile ./models/qwen2.5-1.5b-instruct_q8_0.gguf注
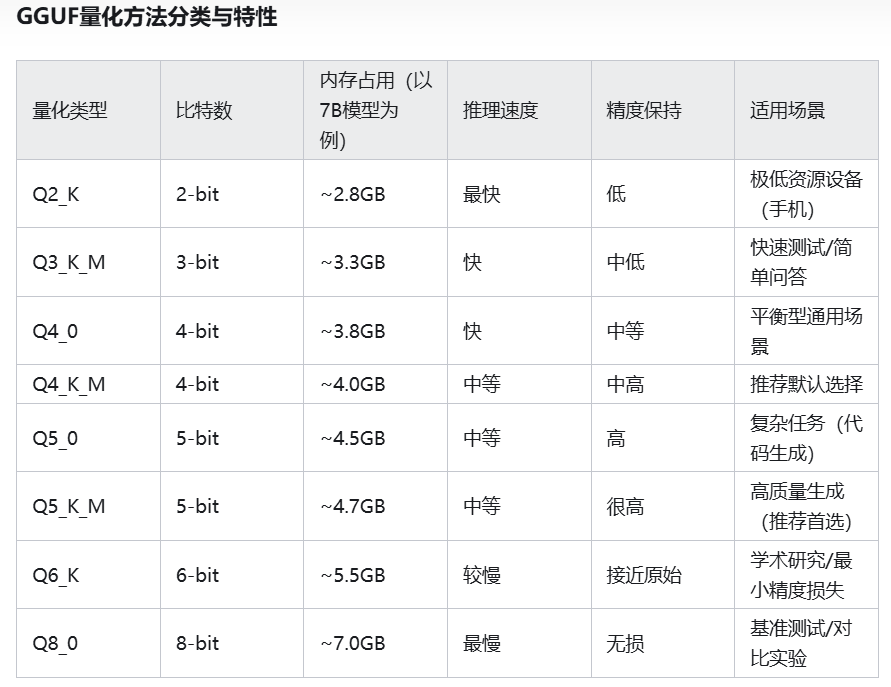
--outtype 是输出类型,代表含义:
| outtype | meaning |
|---|---|
| q2_k | 特定张量(Tensor)采用较高的精度设置,其他的则保持基础级别 |
| q3_k_l, q3_k_m, q3_k_s | 在不同张量上使用不同级别的精度,从而达到性能和效率的平衡 |
| q4_0 | 最初的量化方案,使用 4 位精度 |
| q4_1, q4_k_m, q4_k_s | 提供不同程度的准确性和推理速度,适合需要平衡资源使用的场景 |
| q5_0, q5_1, q5_k_m, q5_k_s | 保证更高准确度的同时,使用更多的资源且推理速度较慢 |
| q6_k, q8_0 | 提供最高的精度,但性能需求大时间消耗多 |
| fp16, f32 | 不量化,保留原始精度 |
运行GGUF格式模型
ollama
高度简化AI模型的本地部署与运行
- 安装ollama
curl -fsSL https://ollama.com/install.sh | sh- 启动ollama
ollama serve- 创建模型参数文件 创建名为"ModelFile"的meta文件,写入内容:
FROM /mnt/workspace/qwen2-0.5b-instruct-q8_0.gguf
# set the temperature to 0.7 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ .Response }}<|im_end|>"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""- 创建自定义模型
ollama create qwen2_0.5b_instruct --file ./ModelFile- 运行模型
ollama run qwen2_0.5b_instructllama.cpp
PocketPal
GGUF模型推送至HuggingFace
- 创建名为
upload.py的Python脚本,写入如下内容
from huggingface_hub import HfApi
api = HfApi()
model_id = "Noviceey/qwen2.5-1.5b-instruct_q8_0"
api.create_repo(model_id, exist_ok=True, repo_type="model")
api.upload_file(
path_or_fileobj="models/qwen2.5-1.5b-instruct_q8_0.gguf",
path_in_repo="qwen2.5-1.5b-instruct_q8_0.gguf",
repo_id=model_id,
)- 从这里获取具有写入权限的HuggingFace Token
- 设置Huggingface token
export HUGGING_FACE_HUB_TOKEN=<paste-your-own-token>- 运行
upload.py脚本
python upload.py编译llama.cpp
- 进入llama.cpp文件夹,进行编译
注
目前官网更推荐使用cmake对程序进行编译
For more details, see build.md
cd llama.cpp
cmake -B build
cmake --build build --config Release